這專案是一個 MLOps Demo,以 文本分類任務 為例,結合 自動化、容器化、版本控制與監控,實作一個 可擴展且可復現 的機器學習開發與部署流程。此專案採用了 Hydra 進行動態配置管理,DVC 來管理資料版本,並透過 MLflow 進行實驗追蹤與模型版本控制,確保模型的最佳化與可復現性。
此外,CI/CD 流程由 Drone 驅動,確保每次模型更新都能自動測試與部署,大幅減少手動操作。資源監控部分,透過 Prometheus 和 Grafana,讓開發者能夠直接掌握 GPU 使用情況與系統運行狀態,確保部署後的系統穩定性與效能。
系統架構圖#
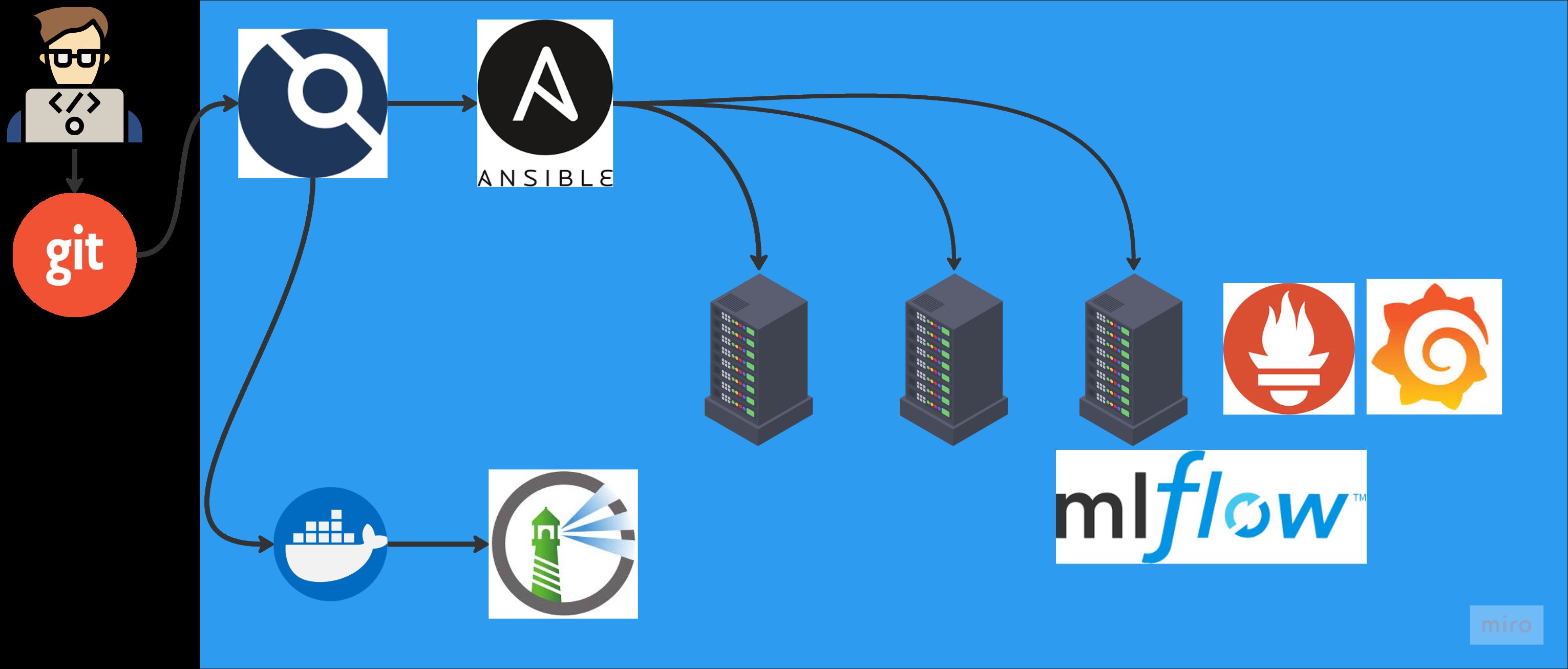
Demo#
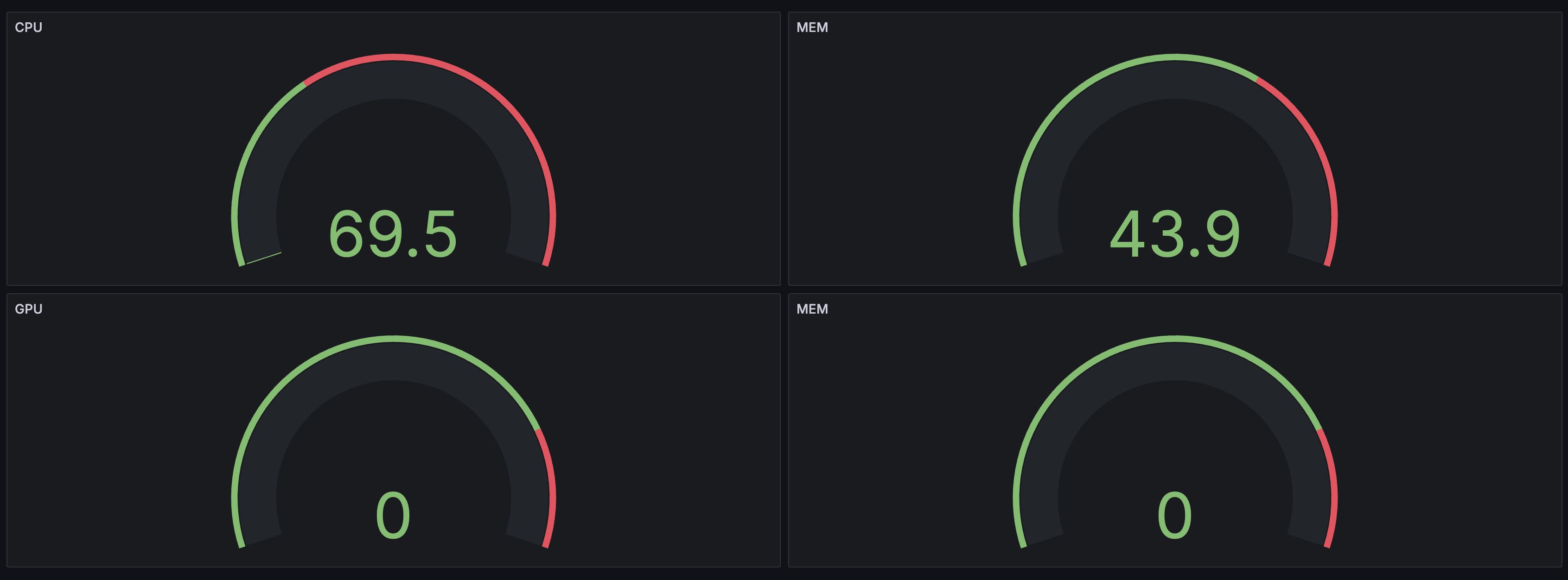
- 資源監控
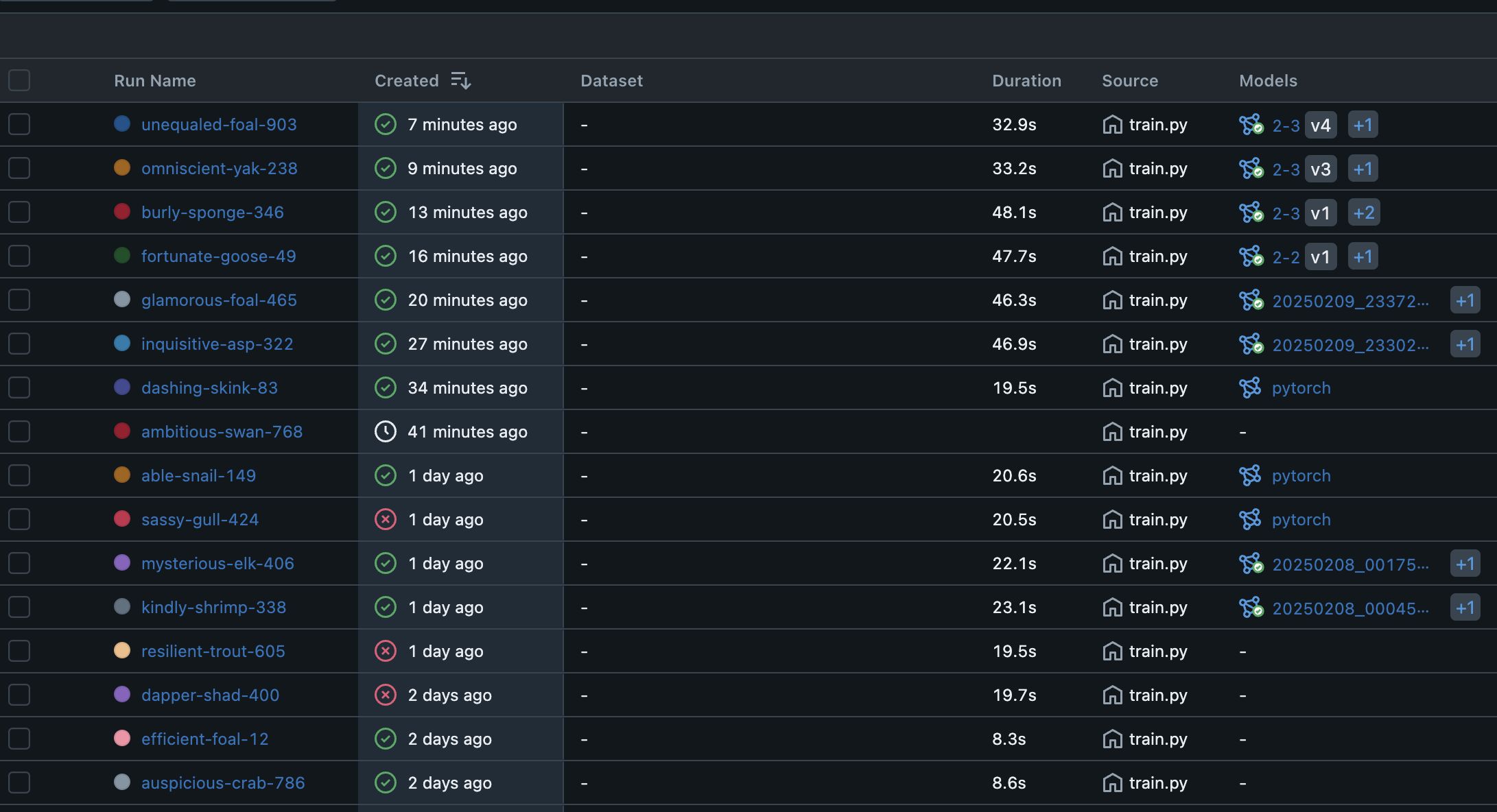
- MLflow 實驗監控
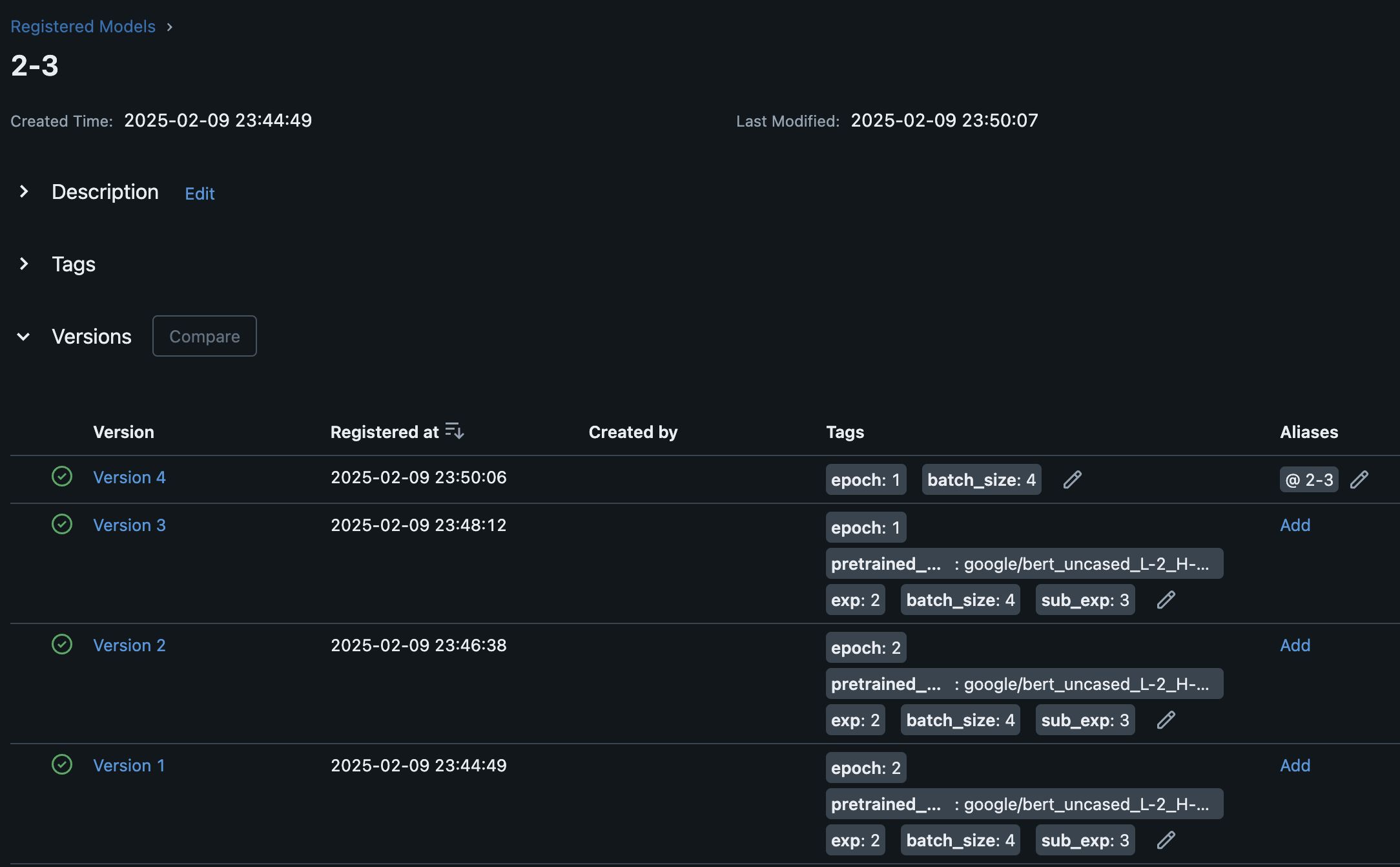
- MLflow 模型版本管理
🔥 專案概述#
本專案目標是建立 機器學習訓練與部署環境,融合 自動化流程、容器化技術及資源監控,為開發者提供 標準化、可擴展且易於管理 的 MLOps 流程
🚀 專案優勢#
✅ MLOps 流程整合
- 結合 Hydra、DVC、MLflow、Drone、Docker、Ansible、Prometheus 和 Grafana,打造全自動化的 ML 研發與部署環境
✅ 數據與模型版本管理,確保可復現性
- DVC 負責資料版本管理,確保數據可追蹤、可重現
- MLflow 進行 實驗記錄與模型版本管理,可多次訓練與模型版本控制
✅ CI/CD 自動化流程,提高開發效率
- Drone 監控 Git 儲存庫的變更,當有新版本推送時,會自動測試、建立 Docker 映像,確保開發流程順暢
✅ 容器化技術,確保環境一致性與可擴展性
- 透過 Docker 和 Harbor 進行模型與應用程式的封裝與管理,確保不同環境下的執行一致性
✅ 監控與可視化,確保系統穩定運行
- Prometheus + Grafana 提供 GPU 使用率、記憶體占用率 監控,避免資源浪費,提高系統可靠性
✅ 動態配置管理,提高靈活性與可維護性
- Hydra 提供高彈性的動態配置,使開發者能輕鬆管理不同實驗與部署參數
🛠 專案架構與流程#
1️⃣ 程式碼管理#
- 開發者撰寫程式碼並推送至 Git 儲存庫,以進行版本控制
2️⃣ CI/CD 自動化#
- Drone 自動化執行測試、封裝成 Docker 映像,確保新版本程式碼可穩定運行
3️⃣ 容器化與映像管理#
- 使用 Docker 打包應用程式與模型,確保環境一致性
- Harbor 進行私有映像倉庫管理,集中存儲與分發映像
4️⃣ 資料與模型版本管理#
- DVC 管理數據版本,確保數據可追蹤與復現
- MLflow 負責實驗與模型版本管理,確保每次訓練的可復現性與最佳化
5️⃣ 自動化部署#
- Ansible 負責多機部署,確保模型與應用能在不同伺服器上快速部署與更新
6️⃣ 監控與資源管理#
- Prometheus + Grafana 提供即時資源監控,包括 GPU 使用率、CPU 負載、記憶體占用率等,確保系統穩定運行
🔧 快速開始#
1️⃣ 開發與版本管理#
- 在本地撰寫程式碼,並推送至 Git 儲存庫
git init
git add .
git commit -m "init"
git remote add origin https://github.com/your-repo.git
git push -u origin main
2️⃣ CI/CD 自動化測試與封裝#
- Drone 自動測試並封裝 Docker 映像
範例: 在 .drone.yml 配置 CI/CD 流程
kind: pipeline
type: docker
name: default
steps:
- name: test
image: python:3.9
commands:
- pip install -r requirements.txt
- pytest
- name: build Docker image
image: docker
commands:
- docker build -t my-app:latest .
- docker push my-app:latest
3️⃣ 資料版本管理#
- 使用 DVC 進行資料版本控制
dvc init
dvc add data/dataset.csv
git add data.dvc .gitignore
git commit -m "trace dataset"
git push origin main
4️⃣ 實驗與模型管理#
- 透過 MLflow 追蹤實驗,記錄指標與超參數,並管理模型版本
範例: 記錄訓練指標與超參數
import mlflow
mlflow.set_experiment("my_experiment")
with mlflow.start_run():
mlflow.log_param("learning_rate", 0.01)
mlflow.log_metric("accuracy", 0.95)
mlflow.log_artifact("model.pkl")
5️⃣ 部署到伺服器#
- 使用 Ansible 自動化部署至指定伺服器
範例: 使用 Ansible 部署應用程式
- hosts: my_server
tasks:
- name: deploy
docker_container:
name: my-app
image: my-app:latest
state: started
ports:
- "8000:8000"
6️⃣ 系統監控#
- 在 Grafana 儀表板 中監控 GPU、記憶體與系統狀態
步驟 1:啟動 Prometheus
在 prometheus.yml 配置監控目標:
global:
scrape_interval: 5s
scrape_configs:
- job_name: "node"
static_configs:
- targets: ["node-exporter:9100"]
- job_name: "gpu"
static_configs:
- targets: ["gpu-exporter:9400"]
然後啟動 Prometheus:
docker run -d --name=prometheus -p 9090:9090 \
-v $(pwd)/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus
步驟 2:啟動 Node Exporter
docker run -d --name=node-exporter -p 9100:9100 prom/node-exporter
步驟 3:安裝並啟動 GPU Exporter
docker run -d --name=gpu-exporter -p 9400:9400 \
--runtime=nvidia \
-e NVIDIA_VISIBLE_DEVICES=all \
nvcr.io/nvidia/k8s/dcgm-exporter:latest
步驟 4:啟動 Grafana
docker run -d --name=grafana -p 3000:3000 grafana/grafana
進入 Grafana,新增 Prometheus 資料來源,並導入 GPU 監控儀表板,如 DCGM Exporter Dashboard