前言#
這篇文章是紀錄如何在Google Colab或本機上微調LLaMA模型或其他LLM,並展示如何使用LLaMA-Factory工具來進行模型訓練。本文將介紹從環境設置到訓練過程的每一個步驟,同時說明如何處理在訓練過程中可能會遇到的問題。還會介紹如何將微調過的LLaMA模型與LoRA模型結合,並提供一些有用的技巧來解決訓練過程中的各種挑戰。最後,透過案例分析,探討較小的訓練資料集對於LLM監督微調的效果與挑戰,分析在資料量有限的情況下,模型是否能有效學習到資料集中的特徵。
Colab Notebook#
本文採用的colab notebook如下:
使用 LLaMA Factory 微調 Llama-3 中文對話模型
本地環境設置#
首先,在本地需要安裝所需的依賴套件。請執行以下命令來安裝huggingface_hub,這樣可以更輕鬆地下載和管理Hugging Face上的模型:
pip install -U "huggingface_hub[cli]"
接著,修改模型名稱和下載位置以符合我們的需求。請根據自己的設置進行調整:
huggingface-cli download --resume-download unsloth/Llama-3.2-3B-Instruct --local-dir /home/user/Documents/models/Llama-3.2-3B-Instruct
拉取並安裝LLaMA-Factory#
接下來,需要從GitHub拉取LLaMA-Factory並安裝必要的依賴套件。這些依賴包括PyTorch和一些評估指標或加速訓練的套件:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
pip install unsloth
啟動網頁UI#
LLaMA-Factory提供了簡單易用的Web UI,可以使用llamafactory-cli來啟動它:
llamafactory-cli webui
這時,你應該能夠看到以下的網頁界面,這是訓練過程的操作平台。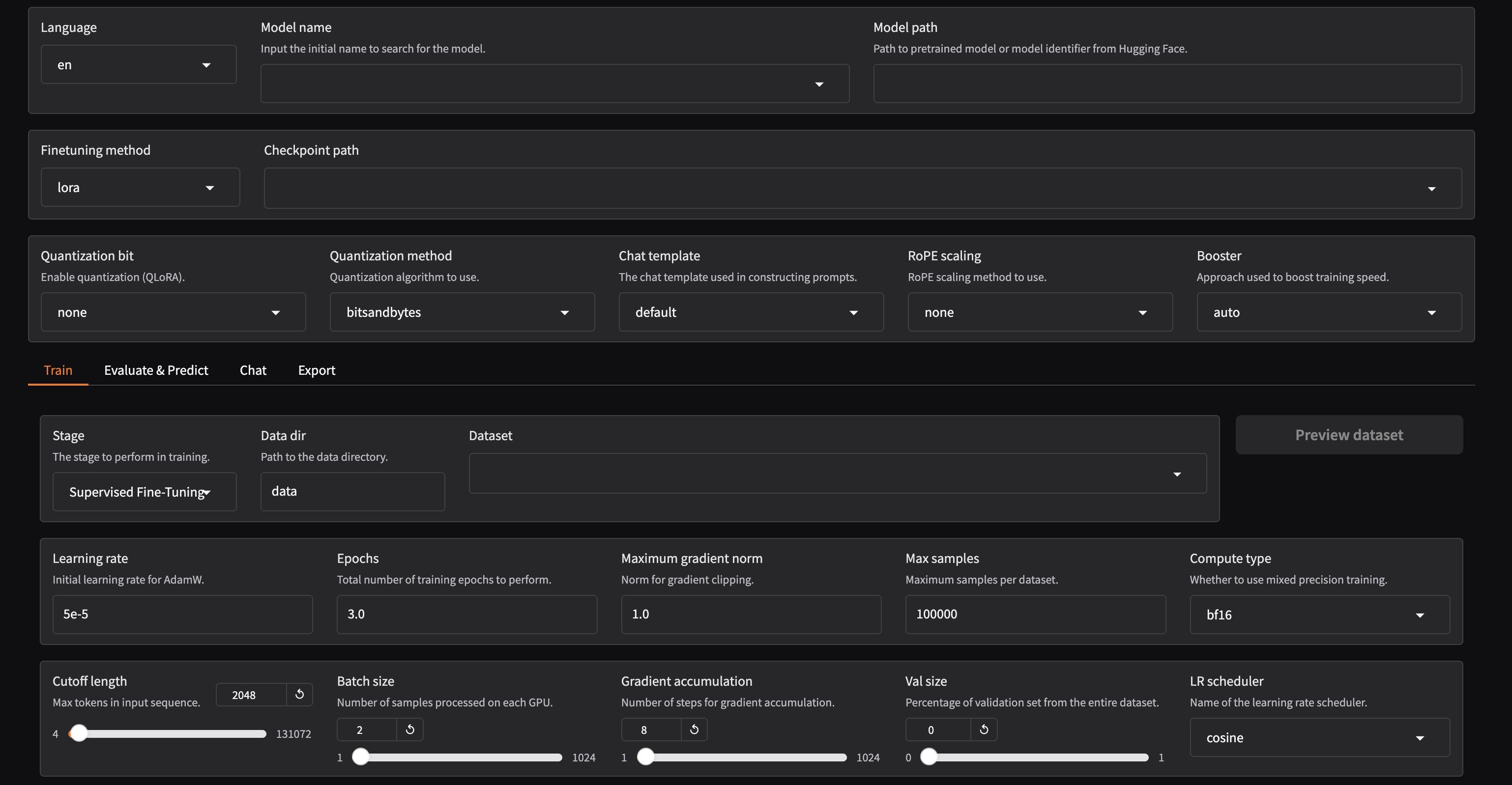
修改模型設定#
進入LLaMA-Factory的資料夾後,找到identity.json檔案,這個檔案包含了關於模型的基本資訊。

將{{name}}替換為你想要的模型名稱,例如“小幫手”,並將{{author}}修改為你的名字。
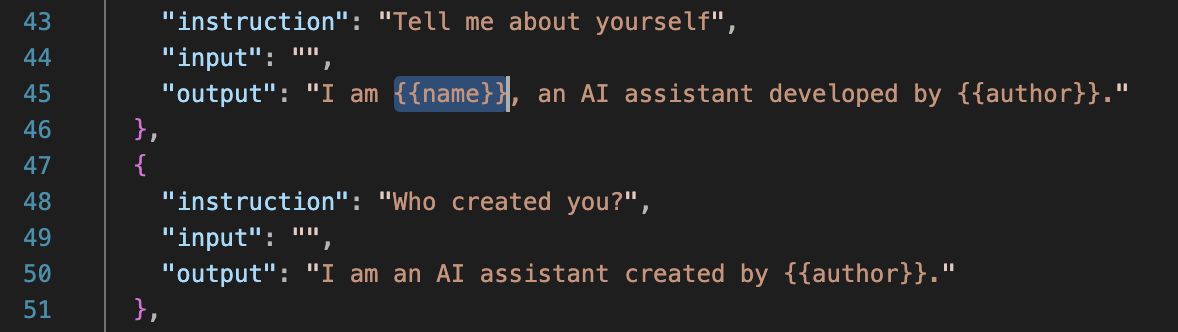
完成後的identity.json應該看起來像這樣:
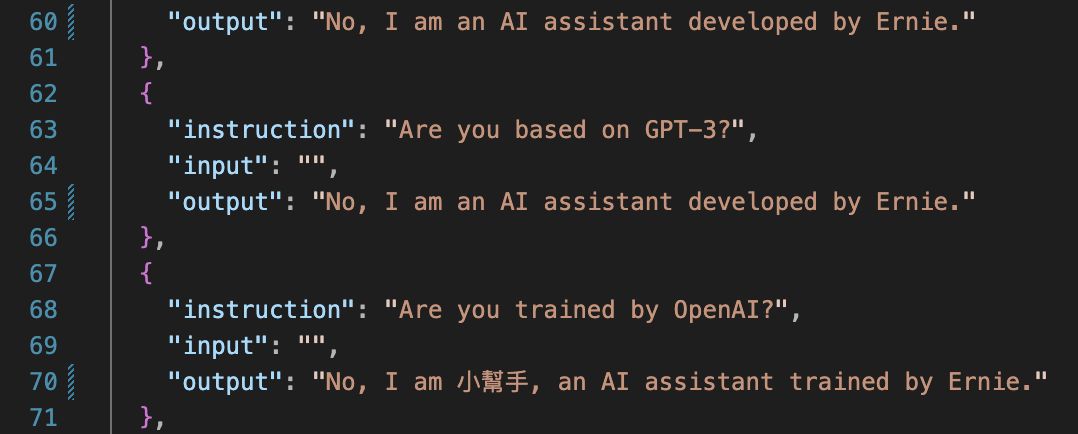
修改資料集設定(可選)#
如果使用的是自訂的資料集(例如自己整理的資料),需要手動將其加入 LLaMA-Factory 的資料集設定中,以便在 WebUI 或 CLI 中正確讀取。這可以透過編輯 dataset_info.json 檔案來完成。
步驟如下:
- 開啟 LLaMA-Factory/dataset_info.json 檔案。
- 在 JSON 結尾加入你的資料集條目,格式如下:
"your-dataset": {
"file_name": "your-dataset.json"
}
舉例來說,若將自訂資料儲存在 data/identity.json,並希望使用 identity 作為資料集名稱,則設定如下:
"identity": {
"file_name": "identity.json"
}
📌 注意:
- file_name 對應的是你放在 data/ 資料夾中的檔名(建議 JSON 格式)。
- 若你的資料集位於其他路徑,可以在 CLI 模式下透過 -dataset_dir 參數指定路徑。
完成設定後,你就可以在 WebUI 的資料集下拉選單中看到這個資料集名稱,或在訓練指令中使用:
--dataset identity
這樣 LLaMA-Factory 就會正確載入你的自訂資料集進行微調。若是第一次製作資料,也可以搭配官方提供的 convert_alpaca.py 腳本或自行撰寫轉換腳本,將資料整理為 instruction 格式。
設定資料集和模型配置#
根據你的需求配置資料集和模型設置。資料集設定為identity,並根據需求調整模型設置。參見下圖的配置示例。下方圖片顯示模型名稱為Qwen,但你可以替換為任何LLM
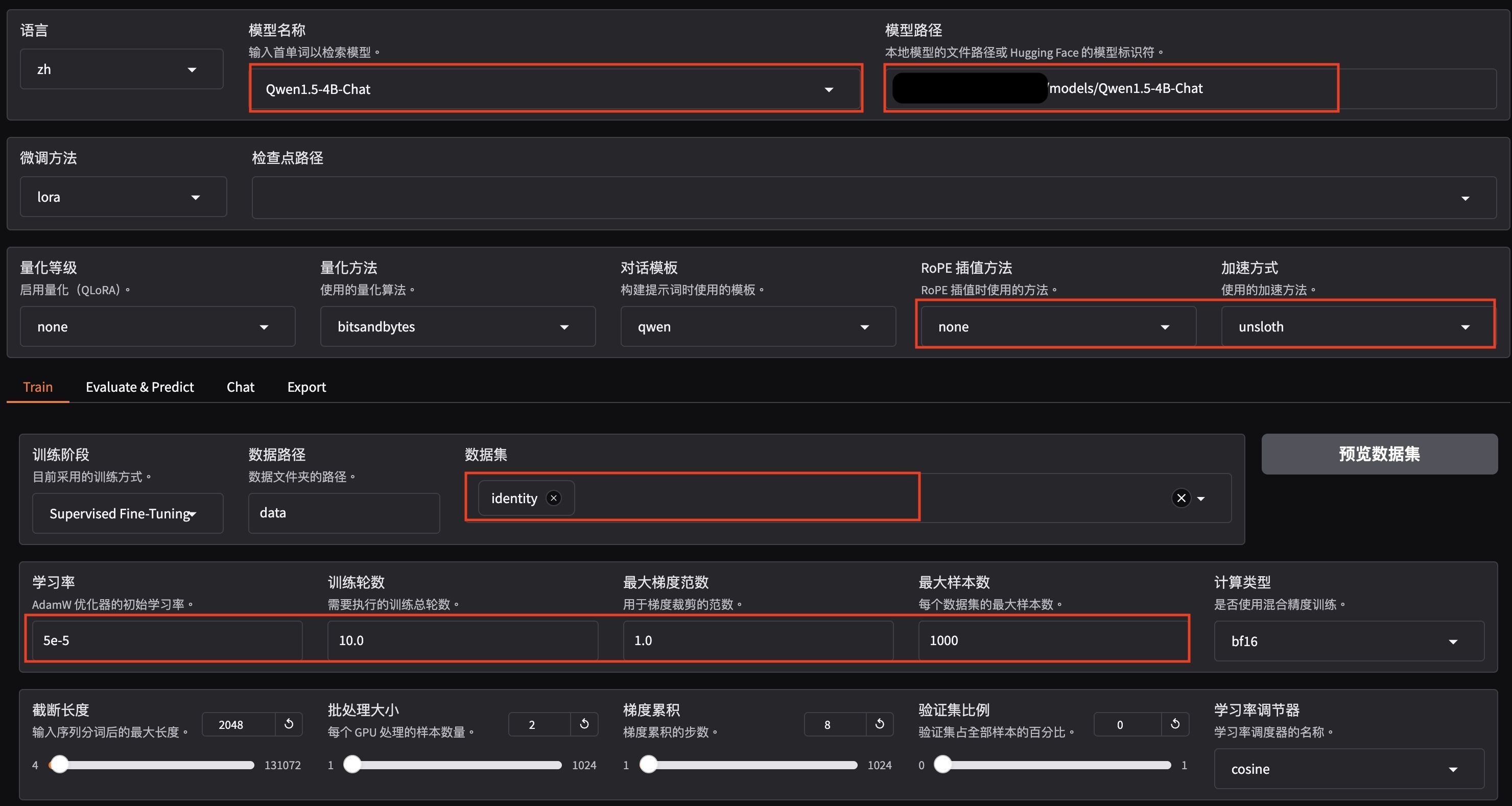
當配置完成後,點擊“開始”按鈕,模型訓練便會啟動。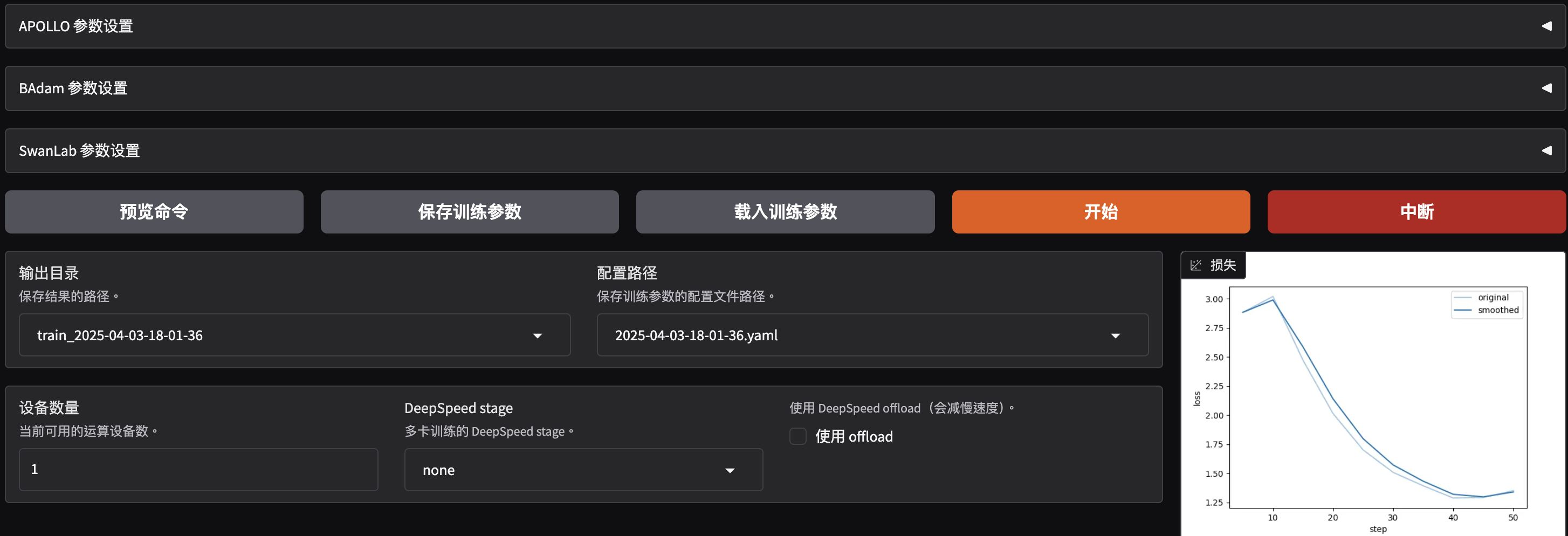
訓練並測試#
訓練完成後,你可以進入“聊天”頁面,開始與模型互動。
例如,你可以問它:“你是誰?”或“介紹你自己”。如果模型回答符合預期,那麼說明訓練成果良好。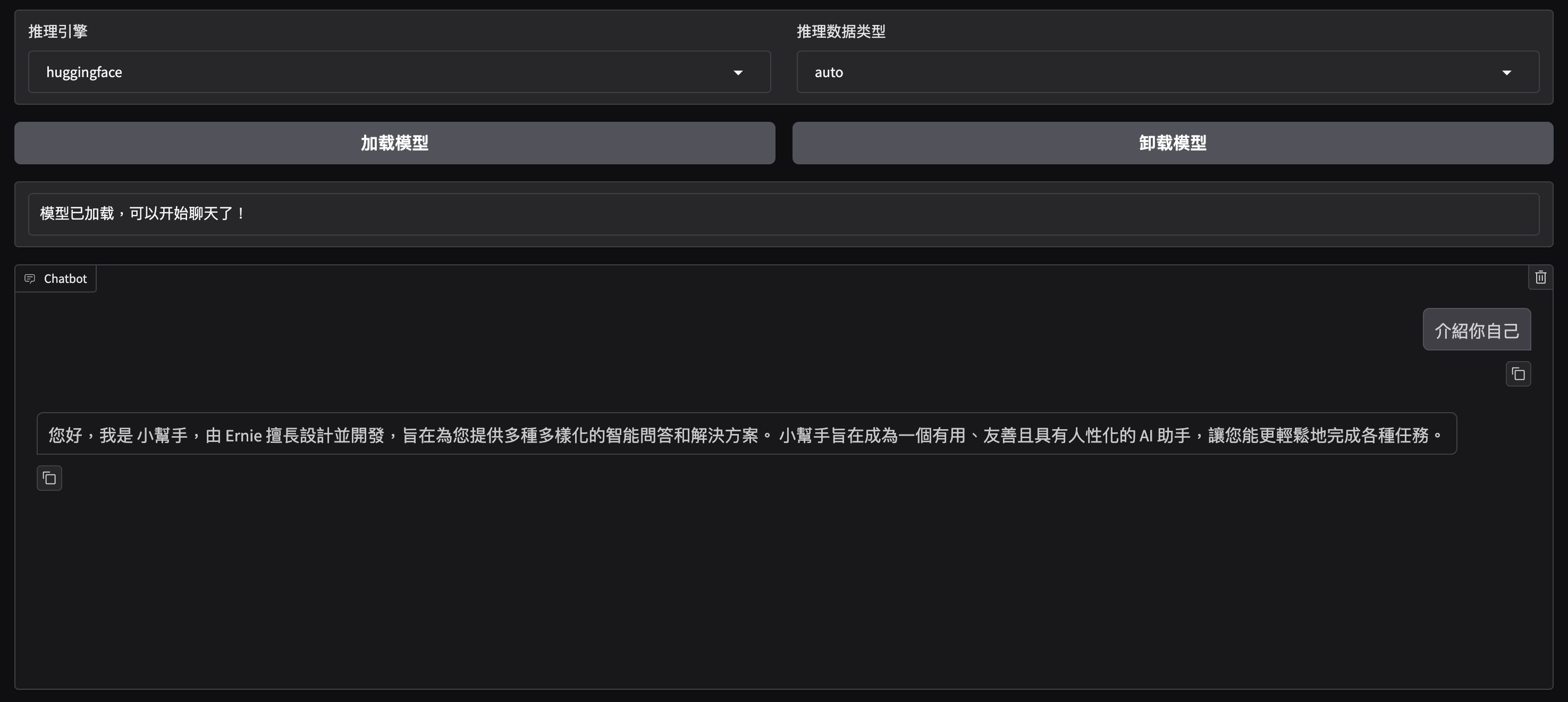
合併LLaMA模型與LoRA#
在訓練完成後,若需要將微調過的LLaMA模型與LoRA模型合併,可以參考以下使用 YAML 撰寫的範例配置文件(位於 LLaMA-Factory/examples/merge_lora/llama3_lora_sft.yaml)進行設定:
### Note: DO NOT use quantized model or quantization_bit when merging lora adapters
### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
adapter_name_or_path: saves/llama3-8b/lora/sft
template: llama3
trust_remote_code: true
### export
export_dir: output/llama3_lora_sft
export_size: 5
export_device: cpu
export_legacy_format: false
這裡指定了原始模型的位置 (model_name_or_path)、LoRA 模型的儲存位置 (adapter_name_or_path),以及輸出合併後模型的資料夾 (export_dir)。請根據實際的訓練路徑修改這些參數。
啟動合併程序#
當完成 YAML 設定後,可以透過以下命令啟動模型合併程序:
python src/merge_lora.py examples/merge_lora/llama3_lora_sft.yaml
此指令會讀取指定的 YAML 檔案,然後將 LoRA 模型參數合併進原始 LLaMA 模型中,並將結果儲存到 export_dir 指定的路徑下。
⚠️ 注意事項:
- 合併時 不要使用量化過的模型,否則可能導致合併失敗或模型效能異常。
- 建議將 export_device 設為 cpu,特別是在 GPU 記憶體有限的環境中執行。
當合併完成後,你就可以將這個新的合併模型用於部署或離線推理,不再需要額外載入 LoRA 權重檔案,讓部署流程更加簡潔。
壓縮LoRA檔案並下載到本地(可選)#
在進行 LLM 和 LoRA 的合併時,有時需要將訓練過程中的 LoRA 參數檔案壓縮,以便於後續合併或下載到本地端。以下是一段在 Colab 上執行的程式碼,目的是將必要的 LoRA 檔案(如 adapter_config.json 和 adapter_model.safetensors)打包成一個壓縮檔,方便下載。這樣不僅可以節省本地端存儲空間,也能加速文件傳輸
!zip llama3_lora_small.zip \
/workspace/output/llama3-8b-lora/2024-04-05-10-30-00/adapter_config.json \
/workspace/output/llama3-8b-lora/2024-04-05-10-30-00/adapter_model.safetensors
files.download("llama3_lora_small.zip")
載入合併後的模型進行推理(可選)#
當你已經成功將 LLaMA 模型與 LoRA 模型合併後,推理流程就變得相對簡單。這時你可以像載入一般 Hugging Face 模型一樣使用 transformers 套件進行推理,而不需要額外掛載 LoRA adapter。
以下是 Python 推理範例程式碼:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 載入合併後模型的目錄
model_path = "output/llama3_lora_sft" # 這裡填入你的 export_dir 路徑
# 載入 tokenizer 和模型
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.float16, device_map="auto")
# 準備輸入提示詞
prompt = "你好,請簡單介紹你自己。"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# 模型生成輸出
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=100,
do_sample=True,
top_k=50,
top_p=0.95,
temperature=0.8
)
# 解碼並顯示模型回應
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
提醒:
- 如果GPU 記憶體不足,可以將 torch_dtype=torch.float16 改為 torch.float32。
- 若使用的是 LLaMA-3 系列模型,記得加上 trust_remote_code=True,以支援其特殊架構。(來源:ChatGPT)
案例探討#
本次實驗使用約 400 筆以特定遊戲角色為主的資料,透過 Google Colab 對 llama3-8b 模型進行微調,資料格式採用指令式的問答格式(Instruction tuning),以模擬實際使用者會詢問的問題。儘管資料量相對有限,但模型在訓練後已能初步掌握遊戲中角色的基本資訊,如屬性、定位、技能效果等。
訓練資料說明#
例如以下資料:
{
"instruction": "分析茜特菈莉、鍾離和藍硯這三位五星角色在護盾功能上的異同。",
"input": "",
"output": "茜特菈莉、鍾離和藍硯都是遊戲中可以給隊友護盾的角色,但各有優劣……(略)"
}
透過類似資料的訓練,模型能夠針對玩家常見的角色問題,提供具有一定參考性的建議。然而,在推理階段仍可能出現錯誤回答或產生幻覺。
微調成果展示:模型輸出與正確答案對比分析#
為驗證微調後模型的表現,我以幾筆測試指令作為輸入,並將 llama3-8b 模型的輸出與正確答案進行比較。這些測試問題皆來自實際玩家在討論角色時常見的疑問,例如角色定位、抽卡建議與新手適用性等。
錯誤案例#
- 原神

- 絕區零

- 崩壞:星穹鐵道

測試問題#
以其中一筆測試舉例:
比較瑪薇卡和阿蕾奇諾兩位火元素角色的定位和強度,在什麼情況下推薦抽取哪一位角色?
✅ 正確答案(來源:網路文章):
瑪薇卡與阿蕾奇諾皆屬火屬性角色,但在隊伍中的功能定位有所差異。瑪薇卡兼具支援與攻擊能力,靈活度高,特別適合在納塔地區的陣容中發揮作用;而阿蕾奇諾則是一位專職輸出手,以高火力見長,能在短時間內造成大量傷害。抽卡建議方面:若隊伍中缺乏強力火系主輸出,且組隊時不太講究元素相容性,阿蕾奇諾會是優先考慮;反之,若偏好一位多功能角色,並希望強化納塔體系隊伍的完整性,即便火力略遜一籌,瑪薇卡依然是不錯的選項。
🤖 模型輸出(錯誤範例):
瑪薇卡和阿蕾奇諾的定位都是火元素輔助,但他們的能力機制和強度不同。瑪薇卡適合需要火元素增益的隊伍,而阿蕾奇諾則偏向需要額外輔助效果的隊伍。在需要火元素增益的隊伍中,瑪薇卡可能更為優先選擇;在需要額外輔助效果的隊伍中,阿蕾奇諾可可能更為優先選擇。
透過上述對比可以觀察到,微調後的模型雖已能理解「角色之間存在差異」的概念,但仍可能在角色定位、機制理解與背景知識整合方面出現幻覺並導致錯誤。這可能源於訓練樣本中關鍵詞過於重複、背景補充不足,或是資料規模太小,而無法覆蓋完整遊戲邏輯所致。
微調成果與分析#
微調後的 LLaMA3-8B 雖能生成語句通順、邏輯清晰的回應,但在知識正確性上仍有不足。例如在比較「瑪薇卡」與「阿蕾奇諾」時,模型將兩者的隊伍定位搞混,甚至遺漏角色的核心技能機制。此類錯誤主因可能是訓練資料量有限,模型學到的是回答的語氣與架構,而非對遊戲角色的深層理解。
此外,資料中缺乏反例與明確對比,導致模型容易將概念混淆,生成出看似合理但實際不準確的回答。要改善這種現象,需增加更多高品質的資料,或結合知識檢索技術(如 RAG)讓模型回應前能參考可靠資訊來源。
著作權聲明#
本篇文章所引用及使用的資料皆來自網路,並僅用於教育與教學目的。所有內容的版權歸原作者所有。